Всем привет! Такой вопрос - метод ADO работает быстрее, чем GetObject?
У меня есть файл (~300 000 тыс строк, более 40 столбцов, каждый день строки добавляются, до тыс в день) Через GetObject открывается 30-45 сек; потом я использую данные из примерно 10 столбцов. Будет ли работа через ADO быстрее?
Всем привет! Такой вопрос - метод ADO работает быстрее, чем GetObject?
У меня есть файл (~300 000 тыс строк, более 40 столбцов, каждый день строки добавляются, до тыс в день) Через GetObject открывается 30-45 сек; потом я использую данные из примерно 10 столбцов. Будет ли работа через ADO быстрее?Michael_S
При просмотре кода класса вдруг увидел "4.0" в том месте, где обычно вижу "8.0". Подозреваю, что опечатка. Возможно, даже невольно ограничивающая функционал по тому же количеству строк - ведь в Excel 4.0 их было всего 16K. Или это сознательный шаг?
не могу ответить, т.к. забыл Скорее всего это был копи-паст откуда то
Michael_S, насколько помню, ADO может работать с закрытыми книгами.
При просмотре кода класса вдруг увидел "4.0" в том месте, где обычно вижу "8.0". Подозреваю, что опечатка. Возможно, даже невольно ограничивающая функционал по тому же количеству строк - ведь в Excel 4.0 их было всего 16K. Или это сознательный шаг?
не могу ответить, т.к. забыл Скорее всего это был копи-паст откуда то
Michael_S, насколько помню, ADO может работать с закрытыми книгами.nerv
Чебурашка стал символом олимпийских игр. А чего достиг ты? Тишина - самый громкий звук
По идее, GetObject д.б. быстрее, чем ADO, при первом запуске. А вот при последующих запусках - не факт. Михаил, можете проверить? И заодно посмотрите такой вариант: [vba]
По идее, GetObject д.б. быстрее, чем ADO, при первом запуске. А вот при последующих запусках - не факт. Михаил, можете проверить? И заодно посмотрите такой вариант: [vba]
Если использовать файл Excel с такими размерами таблицы, то испльзование ADO будет медленнее, причём заметно, достаточно сравнить время на открытие (медленнее будет из-за того, что ADO нужно будет проверять на "правильность" (соответствие определённому на этапе начала работы типу) каждое значение ячейки, плюс структура файла Excel мало приспособлена для оптимальной работы с таблицами. Однозначно будет быстрее работать ADO, если данные загрузить в таблицу Access.
Цитата
(~300 000 тыс строк, более 40 столбцов
Если использовать файл Excel с такими размерами таблицы, то испльзование ADO будет медленнее, причём заметно, достаточно сравнить время на открытие (медленнее будет из-за того, что ADO нужно будет проверять на "правильность" (соответствие определённому на этапе начала работы типу) каждое значение ячейки, плюс структура файла Excel мало приспособлена для оптимальной работы с таблицами. Однозначно будет быстрее работать ADO, если данные загрузить в таблицу Access.anvg
Сообщение отредактировал anvg - Понедельник, 16.12.2013, 10:43
anvg, спасибо за комментарий. В зависимости от машины сейчас файл обрабатывается 40-65 сек, из них 20-45 сек уходит на открытие. Если файл уже открыт, то обрабатывается 25-30 сек. Пробовал перевести данные в Access - получается дольше; из .cvs как текст - тоже дольше получается, правда в этих случаях не "вытягиваются" ненужные данные...
anvg, спасибо за комментарий. В зависимости от машины сейчас файл обрабатывается 40-65 сек, из них 20-45 сек уходит на открытие. Если файл уже открыт, то обрабатывается 25-30 сек. Пробовал перевести данные в Access - получается дольше; из .cvs как текст - тоже дольше получается, правда в этих случаях не "вытягиваются" ненужные данные...Michael_S
Здравствуйте, Михаил. Опишу несколько подробнее. Тестировал на файле формата xlsb в Excel 2010 32bit, Win7 64bit. Файл содержал один лист на 300000 строк, 40 столбцов. Столбцы: 1 – числовой (номер строки), 2 – текстовый, 3 – дата и время, 4 – денежный, 5 – логический (кроме первого, остальные создавались случайным образом, текстовый до 32 символов), с 6 по 40 столбцы с аналогичным содержанием, плюс – верхняя строка заголовков столбцов. То есть использовались все типы, воспринимаемые ADO в Excel. Соответственно, тестирование 1. Через GetObject, с загрузкой в массив 10 последовательных столбцов 9-11сек, почему такая разница с вами, не знаю, предполагаю либо разница в «железе» либо у вас в таблице есть ещё пересчитываемые при открытии формулы. 2. Через ADO, 60-90 секунд, также с выборкой в Recordset 10 столбцов, поэтому и написал, что будет дольше. Предполагаю, что такая долгая загрузка обусловлена проверкой типов данных, хранящихся в ячейках. Базы данных требуют, чтобы столбцы были строго типизированы. ADO определяет тип данных, по умолчанию, по первым 8 строкам, остальные, если не соответствуют требуемому типу, записываются как Null. 3. Эти же данные были загружены в таблицу Access, выборка в Recodrset 10 столбцов даже по сети около 2 секунд (сеть 1Гб). Но в этом случае требуется, чтобы данные всегда хранились в базе Access. Из Excel осуществляется: чтение, обновление, добавление данных, в этом случае будет быстро. Если данные каждый раз перегружать из Excel в Access, то естественно это будет долго. Я же проверял только скорость получения данных из таблицы базы Access в Recordset. В общем, чтобы определяться, что лучше – нужно знать конкретную структуру данных и алгоритм обработки.
Здравствуйте, Михаил. Опишу несколько подробнее. Тестировал на файле формата xlsb в Excel 2010 32bit, Win7 64bit. Файл содержал один лист на 300000 строк, 40 столбцов. Столбцы: 1 – числовой (номер строки), 2 – текстовый, 3 – дата и время, 4 – денежный, 5 – логический (кроме первого, остальные создавались случайным образом, текстовый до 32 символов), с 6 по 40 столбцы с аналогичным содержанием, плюс – верхняя строка заголовков столбцов. То есть использовались все типы, воспринимаемые ADO в Excel. Соответственно, тестирование 1. Через GetObject, с загрузкой в массив 10 последовательных столбцов 9-11сек, почему такая разница с вами, не знаю, предполагаю либо разница в «железе» либо у вас в таблице есть ещё пересчитываемые при открытии формулы. 2. Через ADO, 60-90 секунд, также с выборкой в Recordset 10 столбцов, поэтому и написал, что будет дольше. Предполагаю, что такая долгая загрузка обусловлена проверкой типов данных, хранящихся в ячейках. Базы данных требуют, чтобы столбцы были строго типизированы. ADO определяет тип данных, по умолчанию, по первым 8 строкам, остальные, если не соответствуют требуемому типу, записываются как Null. 3. Эти же данные были загружены в таблицу Access, выборка в Recodrset 10 столбцов даже по сети около 2 секунд (сеть 1Гб). Но в этом случае требуется, чтобы данные всегда хранились в базе Access. Из Excel осуществляется: чтение, обновление, добавление данных, в этом случае будет быстро. Если данные каждый раз перегружать из Excel в Access, то естественно это будет долго. Я же проверял только скорость получения данных из таблицы базы Access в Recordset. В общем, чтобы определяться, что лучше – нужно знать конкретную структуру данных и алгоритм обработки.anvg
Добрый вечер, а кто может сказать, почему у меня этот класс не хочет работать с более чем 65к строк? Эксель 2010. Два часа голову ломал, а оказалось, что ошибка в запросе..
Добрый вечер, а кто может сказать, почему у меня этот класс не хочет работать с более чем 65к строк? Эксель 2010. Два часа голову ломал, а оказалось, что ошибка в запросе..SkyPro
skypro1111@gmail.com
Сообщение отредактировал SkyPro - Пятница, 10.01.2014, 18:19
Подскажите пожалуйста, возможно ли использовать INNER JOIN, а также Select в Select? Постоянно рунается на синтаксис. Файлик прикладываю. Первые 2 таблицы - исходные, третья результат, который должен быть.
Код: ADO.Query ("Select City, sum(Number) from [A1:B9] as table1 INNER JOIN [D1:E5] as table2 ON Number=Number_city Group by City")
Добрый день!
Подскажите пожалуйста, возможно ли использовать INNER JOIN, а также Select в Select? Постоянно рунается на синтаксис. Файлик прикладываю. Первые 2 таблицы - исходные, третья результат, который должен быть.
Код: ADO.Query ("Select City, sum(Number) from [A1:B9] as table1 INNER JOIN [D1:E5] as table2 ON Number=Number_city Group by City")MerLen
Добрый день. Файл не смотрел, однако в запросе у вас не указано название листа(ов) с которых берутся данные. Запрос должен выглядеть тогда так "Select City, sum(Number) from [ИмяЛиста$A1:B9] as table1 INNER JOIN [ИмяЛиста$D1:E5] as table2 ON Number=Number_city Group by City" Успехов.
Добрый день. Файл не смотрел, однако в запросе у вас не указано название листа(ов) с которых берутся данные. Запрос должен выглядеть тогда так "Select City, sum(Number) from [ИмяЛиста$A1:B9] as table1 INNER JOIN [ИмяЛиста$D1:E5] as table2 ON Number=Number_city Group by City" Успехов.anvg
SELECT d.City AS City, SUM(a.Number) AS Num FROM [Исходные данные$a:b] AS a,[Исходные данные$d:e] AS d WHERE a.Number=d.Number_city GROUP BY d.City
[/vba]
Чтобы получить данные как требуется в примере:
[vba]
Код
SELECT d.City AS City, SUM(a.Number) AS Num FROM [Исходные данные$a:b] AS a RIGHT JOIN [Исходные данные$d:e] AS d ON a.Number=d.Number_city GROUP BY d.City
[/vba]
Иннер джойн в этом запросе писать необязательно:
[vba]
Код
SELECT d.City AS City, SUM(a.Number) AS Num FROM [Исходные данные$a:b] AS a,[Исходные данные$d:e] AS d WHERE a.Number=d.Number_city GROUP BY d.City
[/vba]
Чтобы получить данные как требуется в примере:
[vba]
Код
SELECT d.City AS City, SUM(a.Number) AS Num FROM [Исходные данные$a:b] AS a RIGHT JOIN [Исходные данные$d:e] AS d ON a.Number=d.Number_city GROUP BY d.City
У меня есть еще один вопросик возможно ли написать такой запрос, чтобы значения одного исходного столбца "превратились" в столбцы результирующего? Альтернативный результат с сводными, но не хочется их использовать
Спасибо большое за помощь! Все получилось!
У меня есть еще один вопросик возможно ли написать такой запрос, чтобы значения одного исходного столбца "превратились" в столбцы результирующего? Альтернативный результат с сводными, но не хочется их использовать MerLen
возможно ли написать такой запрос, чтобы значения одного исходного столбца "превратились" в столбцы результирующего?
Можно. Подобный запрос "звучит" примерно так:
[vba]
Код
TRANSFORM Sum(Продажи) SELECT Город, Продукт FROM Лист1 GROUP BY Город, Продукт PIVOT [Тип магазина]
[/vba] Не бойтесь, я сам это тоже на память не помню - это мне Мастер запросов в MS Access помог, там это называется "перекрестный запрос".
Соответственно, применительно к листу Excel это как-то так:
[vba]
Код
Sub selectData()
Dim rst As Object Set rst = CreateObject("ADODB.Recordset")
rst.Open _ "TRANSFORM Sum(Продажи) " & _ "SELECT Город, Продукт " & _ "FROM [Лист1$A2:D23] " & _ "GROUP BY Город, Продукт " & _ "PIVOT [Тип магазина]" _ , _ "Provider=Microsoft.ACE.OLEDB.12.0;" & _ "Data Source=" & ThisWorkbook.FullName & ";" & _ "Extended Properties='Excel 12.0;HDR=Yes'"
[Лист1!G15].CopyFromRecordset rst
'ЗАГОЛОВКИ Dim i As Integer Dim arrName() As Variant ReDim Preserve arrName(0 To rst.Fields.Count - 1) For i = 0 To rst.Fields.Count - 1 arrName(i) = rst.Fields(i).Name Next i With Range("G14").Resize(1, rst.Fields.Count) .Value = arrName .Font.Bold = True End With
End Sub
[/vba] О заголовках результата надо будет позаботиться самостоятельно, анализируя коллекцию rst.Fields (P.S. я добавил вывод заголовков в код).
возможно ли написать такой запрос, чтобы значения одного исходного столбца "превратились" в столбцы результирующего?
Можно. Подобный запрос "звучит" примерно так:
[vba]
Код
TRANSFORM Sum(Продажи) SELECT Город, Продукт FROM Лист1 GROUP BY Город, Продукт PIVOT [Тип магазина]
[/vba] Не бойтесь, я сам это тоже на память не помню - это мне Мастер запросов в MS Access помог, там это называется "перекрестный запрос".
Соответственно, применительно к листу Excel это как-то так:
[vba]
Код
Sub selectData()
Dim rst As Object Set rst = CreateObject("ADODB.Recordset")
rst.Open _ "TRANSFORM Sum(Продажи) " & _ "SELECT Город, Продукт " & _ "FROM [Лист1$A2:D23] " & _ "GROUP BY Город, Продукт " & _ "PIVOT [Тип магазина]" _ , _ "Provider=Microsoft.ACE.OLEDB.12.0;" & _ "Data Source=" & ThisWorkbook.FullName & ";" & _ "Extended Properties='Excel 12.0;HDR=Yes'"
[Лист1!G15].CopyFromRecordset rst
'ЗАГОЛОВКИ Dim i As Integer Dim arrName() As Variant ReDim Preserve arrName(0 To rst.Fields.Count - 1) For i = 0 To rst.Fields.Count - 1 arrName(i) = rst.Fields(i).Name Next i With Range("G14").Resize(1, rst.Fields.Count) .Value = arrName .Font.Bold = True End With
End Sub
[/vba] О заголовках результата надо будет позаботиться самостоятельно, анализируя коллекцию rst.Fields (P.S. я добавил вывод заголовков в код).Gustav
то ли лыжи у меня не едут, то ли какие-нить настройки ADO по дефолту... короче, не работает у меня метод ToArray() из версии 0.5
и начинает работать, только если в коде метода перед строкой [vba]
Код
Data = Me.Recordset.GetRows()
[/vba] добавить такую: [vba]
Код
Me.Recordset.MoveFirst
[/vba]
внимание, вопрос к знатокам: а нужна ли такая "смазка для лыж" или правильнее поправить что-нибудь где-нибудь в строке соединения или настройках? дополнительные вопросы для получения суперприза: что и где?
спасибо за внимание.
то ли лыжи у меня не едут, то ли какие-нить настройки ADO по дефолту... короче, не работает у меня метод ToArray() из версии 0.5
и начинает работать, только если в коде метода перед строкой [vba]
Код
Data = Me.Recordset.GetRows()
[/vba] добавить такую: [vba]
Код
Me.Recordset.MoveFirst
[/vba]
внимание, вопрос к знатокам: а нужна ли такая "смазка для лыж" или правильнее поправить что-нибудь где-нибудь в строке соединения или настройках? дополнительные вопросы для получения суперприза: что и где?
Добрый день! Подскажите пожалуйста, где можно найти "корень зла". Сделала файлик с использованием ADO. При тестировании на разных компьютерах, получилось, что на части комьютеров все работает отлично, а на части нет (ошибок не выводит, но и данных тоже). Судя по всему в Recordset - не попадают данные. Может в настройках Excel какой блокатор стоит?
Добрый день! Подскажите пожалуйста, где можно найти "корень зла". Сделала файлик с использованием ADO. При тестировании на разных компьютерах, получилось, что на части комьютеров все работает отлично, а на части нет (ошибок не выводит, но и данных тоже). Судя по всему в Recordset - не попадают данные. Может в настройках Excel какой блокатор стоит?MerLen
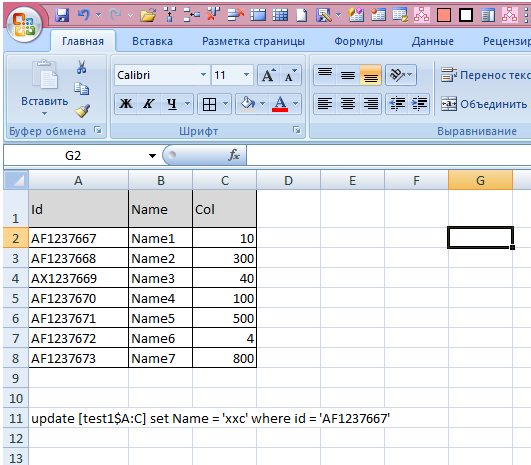
Всем привет! При использовании обсуждаемого класса на указанной на картинке таблице с запросом на обновление вылезает ошибка 'В операции должен использоваться обновляемый запрос'.
(книга открыта для редактирования, макросы включены и т.п.)
Это значит: а) у ADO нет права записи в книгу б) ... ?
что в этой ситуации можно сделать? селекты работают отлично.
Запрос на удаление выдает 'невозможно удаление записей из указанных таблиц'
Т.е. у ADO нет права изменять книгу. Где это можно включить? Я не указал какой-то параметр ADO?
подскажите плз, кто знает! ))
Всем привет! При использовании обсуждаемого класса на указанной на картинке таблице с запросом на обновление вылезает ошибка 'В операции должен использоваться обновляемый запрос'.
(книга открыта для редактирования, макросы включены и т.п.)
Это значит: а) у ADO нет права записи в книгу б) ... ?
что в этой ситуации можно сделать? селекты работают отлично.
Запрос на удаление выдает 'невозможно удаление записей из указанных таблиц'
Т.е. у ADO нет права изменять книгу. Где это можно включить? Я не указал какой-то параметр ADO?
Такого можно добиться при обновлении, если, например, подключение у вас только на чтение. Маловато информации для точного ответа. Для этого случая проверьте Connection.Mode - нужно, чтобы было 16 или 3 (можно прописать в строке подключения Mode=16). P. S. А зачем вам синтаксис для таблицы [test1$A:C]? Вполне же достаточно просто [test1$] или у вас там ещё какие-то данные сбоку?
Цитата
с запросом на обновление вылезает ошибка
Такого можно добиться при обновлении, если, например, подключение у вас только на чтение. Маловато информации для точного ответа. Для этого случая проверьте Connection.Mode - нужно, чтобы было 16 или 3 (можно прописать в строке подключения Mode=16). P. S. А зачем вам синтаксис для таблицы [test1$A:C]? Вполне же достаточно просто [test1$] или у вас там ещё какие-то данные сбоку?anvg
Сообщение отредактировал anvg - Четверг, 10.04.2014, 07:03










 Скорее всего это был копи-паст откуда то
Скорее всего это был копи-паст откуда то